| 8:00 | Registration |
| 8:20 | Opening and Welcome |
| 8:30 | General Auditory Processing Talks |
| 9:45 | Break & Poster Setup (15 mins) |
| 10:00 | Speech Perception and Production Talks |
| 11:15 | Poster Setup (15 mins) |
| 11:30 | Poster Session |
| 1-5 | Music, Pitch, and Timbre Perception and Production |
| 6-9 | Timing and Temporal Processing |
| 10-21 | Auditory Attention, Auditory Scene Analysis, Cross-Modal Correspondences, Multisensory Integration |
| 22-27 | Speech Perception and Production |
| 12:30 | Lunch Break (60 minutes) |
| 1:30 | Keynote Address: Emily Elliott (Louisiana State University) |
| 2:00 | Music Perception Talks |
| 3:00 | Break (15 minutes) |
| 3:15 | Auditory Perception Across the Lifespan Talks |
| 4:15-5:00 | Business Meeting (APCAM, APCARF, and AP&C) |
Welcome to the 17th annual Auditory Perception, Cognition, and Action Meeting (APCAM 2018) at the Hyatt Regency Hotel in New Orleans! Since its founding in 2001-2002, APCAM's mission has been "...to bring together researchers from various theoretical perspectives to present focused research on auditory cognition, perception, and aurally guided action." We believe APCAM to be a unique meeting in containing a mixture of basic and applied research from different theoretical perspectives and processing accounts using numerous types of auditory stimuli (including speech, music, and environmental noises). As noted in previous programs, the fact that APCAM continues to flourish is a testament to the openness of its attendees to considering multiple perspectives, which is a principle characteristic of scientific progress.
As announced at APCAM 2017 in Vancouver, British Columbia, APCAM is now affiliated with the journal Auditory Perception and Cognition (AP&C), which features both traditional and open-access publication options. Presentations at APCAM will be automatically considered for a special issue of AP&C, and in addition, we encourage you to submit your other work on auditory science to AP&C. Feel free to stop at the Taylor & Francis exhibitor booth at the Psychonomic Society meeting for additional information or to see a sample copy. Also announced at the Vancouver meeting is APCAM's affiliation with the Auditory Perception and Cognition Research Foundation (APCARF). This non-profit foundation is charged with furthering research on all aspects of audition. The $30 registration fee for APCAM provides a one-year membership for APCARF, which includes an individual subscription to AP&C and reduced open-access fees for AP&C.
As an affiliate meeting of the 59th Annual Meeting of the Psychonomic Society, APCAM is indebted to the Psychonomic Society for material support regarding the meeting room, AV equipment, and poster displays. We acknowledge and are grateful for their support, and we ask that you pass along your appreciation to the Psychonomic Society for their support of APCAM. We would also like to thank Ian Kpachavi of Carleton College for creating our new APCAM logo, the WRAP Lab and Villanova University for hosting the online version of this year's program and providing supplies for name badges, and Mike Russell of Washburn University for coordinating a live-stream of APCAM. If you have colleagues who are unable to join us in New Orleans, you can point them to our APCAM Facebook account, which will be live-streaming the spoken sessions throughout the day (barring technical difficulties).
We appreciate all of our colleagues who contributed to this year's program. We thank you for choosing to share your work with us, and we hope you will continue to contribute to APCAM in the future. This year's program features spoken sessions on speech, music, developmental processes, and general auditory processing, as well as a wide variety of poster topics. We are confident that everyone attending APCAM will find something interesting, relevant, and thought-provoking.
If there are issues that arise during the meeting, or if you have thoughts for enhancing future meetings, do not hesitate to contact any committee member (pictured below). We wish you a pleasant and productive day at APCAM!
Sincerely,





The spoken sessions and business meeting will take place in STRAND 11B, which is on Level 2 of the Hyatt Regency New Orleans Hotel (starred below).
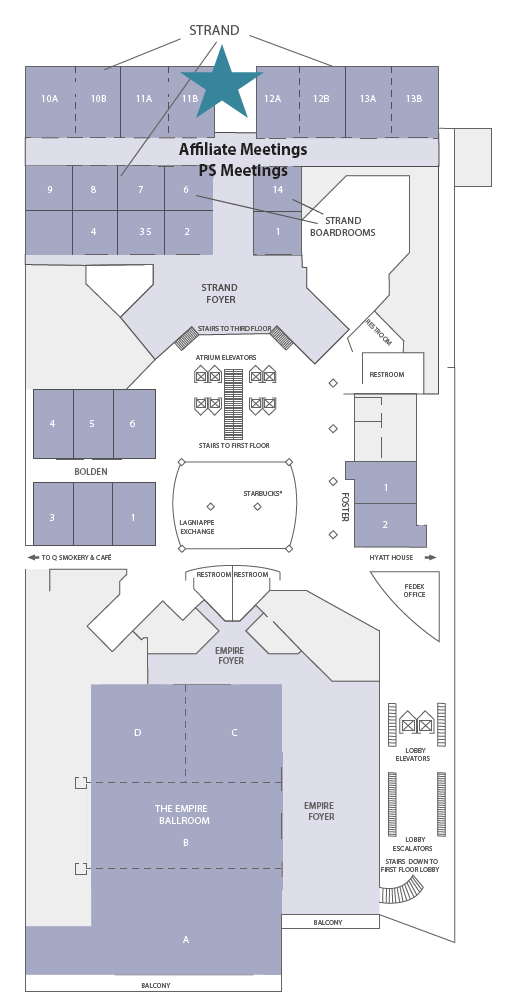
Presentation titles are clickable links to the associated abstract.
| 8:00 | Registration | |
| 8:20 | Opening and Welcome | |
| General Auditory Processing | ||
| 8:30 | How and when do you know what you hear? | Matson Ogg* (University of Maryland) Robert Slevc (University of Maryland) |
| 8:45 | Amplitude envelope manipulation: A cost-efficient solution for auditory alarm annoyance reduction | Sharmila Sreetharan* (McMaster University) Joseph Schlesinger (Vanderbilt University Medical Center) Mike Schutz (McMaster University) |
| 9:00 | Cross-modal attention in emergency medical professionals vs. regular drivers | Gillian Murphy (University College Cork) |
| 9:15 | Planning serial order in production of music and language | Peter Pfordresher* (University at Buffalo) Zach Schendel (Ohio State University and Netflix) Caroline Palmer (McGill University) |
| 9:30 | Distinct mechanisms of auditory imagery differentially influence perception | Xing Tian (New York University Shanghai) |
| 9:45 | Break & Poster Setup (15 mins) | |
| Speech Perception and Production | ||
| 10:00 | The effects of morphological context on speech perception are task dependent | Karan Banai* (University of Haifa) Niveen Omar (University of Haifa) |
| 10:15 | Top-down lexical knowledge directly influences early speech perception | Laura Getz* (Villanova University) Joseph Toscano (Villanova University) |
| 10:30 | The role of rhythm in understanding speech in difficult listening situations | Devin McAuley* (Michigan State University) Sarah Dec (Michigan State University) Yi Shen (Indiana University) Gary Kidd (Indiana University) |
| 10:45 | Differences in intensity discrimination predicted by self-reported speech recognition difficulty | Joseph Toscano* (Villanova University) Gwen Saccocia (Villanova University) |
| 11:00 | Social judgments of digitally manipulated stuttered speech: An evaluation of self-disclosure on cognition and explicit bias | Ashley Ferguson (Kent State University) Hayley Arnold (Kent State University) Jennifer Roche* (Kent State University) |
| 11:15 | Poster Setup | |
| 11:30 | Poster Session | |
| Music, Pitch, and Timbre Perception and Production | ||
| 1 (193) | Genre-specific music training does not alter auditory object perception | Cassandra Doolittle (University of Wisconsin-Milwaukee) |
| 2 (194) | Predicting pitch's influence on instrument timbres and vowels | Michael Hall* (James Madison University) Thomas Rohaly (James Madison University) |
| 3 (195) | Effects of rise time on timbre perception | Lee Jung An (Grand Valley State University) |
| 4 (196) | Wrong notes in melodies: Asymmetry in response time to up vs. down alterations | W. Jay Dowling* (The University of Texas at Dallas) Rachna Raman (The University of Texas at Dallas) |
| 5 (197) | Singing variants of the same tune: Bird and human songs follow similar statistical structures (sometimes) | Kristopher J. Patten (Arizona State University) |
| Timing and Temporal Processing | ||
| 6 (198) | WITHDRAWN: Temporal processing in cortico-striatal networks: Investigating the effects of rhythmic priming on dopamine reactivation for fine-grained sequential motor tasks via the emergent simulator | Mehmet Vurkaç (Seattle University) Brigid Kelly (Seattle University) Yune S. Lee (The Ohio State University) Mary Jane Perdiguerra (Seattle University) Edward Gao (Seattle University) Nhan Tim Nguyen (Seattle University) Kalana de Silva Agampodi (Seattle University) |
| 7 (199) | Revisiting the bimanual advantage in synchronization-continuation tapping | Carolyn Kroger* (Michigan State University) Devin McAuley (Michigan State University) |
| 8 (200) | Moving in time: A neural network model of rhythm-based motor sequence production | Omar Zeid (Boston University) |
| 9 (201) | Neurobiological markers of rhythm perception in children with Specific Language Impairment | Leyao Yu* (Vanderbilt University) Brett Myers (Vanderbilt University) Reyna Gordon (Vanderbilt University) |
| Auditory Attention, Auditory Scene Analysis, Cross-Modal Correspondences, Multisensory Integration | ||
| 10 (202) | Discovering which features contribute to identifiability of everyday sounds and objects | Margaret Duff* (Army Research Laboratory) Kelly Dickerson (Army Research Laboratory) |
| 11 (203) | There's a bad noise on the rise: Looming sounds produce behavioural attentional capture | John Marsh* (University of Gavle) Robert Ljung (University of Gavle) François Vachon (Université Laval) Florian Pausch (Aachen University) Robin Persson Liljenberg (University of Gavle) Rob Hughes (Royal Holloway, University of London) |
| 12 (204) | The effect of feedback on the auditory perception of elevation | Stephanie Jones* (Washburn University) Holly Johnston (Washburn University) Cindy Nebel (Washburn University) |
| 13 (205) | Perception of approaching and retreating sounds in a two-dimensional space: Effect of visual stimuli on perceptual accuracy | Holly Johnston* (Washburn University) Stephanie Jones (Washburn University) Mike Russell (Washburn University) |
| 14 (206) | Influence of response method on the perception of motion in the vertical plane | Mike Russell* (Washburn University) Holly Johnston (Washburn University) Stephanie Jones (Washburn University) |
| 15 (207) | Hearing water temperature: Characterizing the development of cross-modal auditory event perception | Tanushree Agrawal* (University of California, San Diego) Michelle Lee (UCSD) Amanda Calcetas (UCSD) Danielle Clarke (UCSD) Naomi Lin (UCSD) Adena Schachner (UCSD) |
| 16 (208) | Auditory alerting modulates processing of peripheral visual stimuli in Eriksen flanker task | Cailey Salagovic* (University of Colorado Denver) Carly Leonard (University of Colorado Denver) |
| 17 (209) | The effect of the similarity of events on change deafness | Caroline Cole (James Madison University) Michael Hall* (James Madison University) Thomas Rohaly (James Madison University) |
| 18 (210) | Differential effects in bimodal directional Stroop interference | Chris Koch (George Fox University) |
| 19 (211) | Face recognition is disrupted by irrelevant speech | Raoul Bell* (Heinrich Heine University Düsseldorf) Laura Mieth (Heinrich Heine University Düsseldorf) Jan Philipp Röer (Witten/ Herdecke University) Axel Buchner (Heinrich Heine University Düsseldorf) |
| 20 (212) | Beauty is in the ear of the belistener | Kristopher J. Patten* (Arizona State University) Jayci Landfair* (Arizona State University) |
| 21 (213) | Auditory-visual integration across temporal and semantic incongruence | Laurie Heller* (Carnegie Mellon University) Xiaomeng Zhang (Carnegie Mellon University) |
| Speech Perception and Production | ||
| 22 (214) | Putting Monty Python's Lumberjack Song to the test: Measuring eye movements to gauge the effect of implicit gender-role biases on online speech perception | Boaz Ben-David* (Interdisciplinary Center Herzliya) Juliet Gavison (Interdisciplinary Center Herzliya) Marisa Ourieff (Interdisciplinary Center Herzliya) Karin Sendel (Interdisciplinary Center Herzliya) |
| 23 (215) | Linguistic, perceptual, and cognitive factors underlying musicians' benefits in noise-degraded speech perception | Jessica Yoo* (University of Memphis) Gavin Bidelman (University of Memphis) |
| 24 (216) | Noise increases listening effort, regardless of working memory capacity | Violet Brown (Washington University in St. Louis) Julia Strand* (Carleton College) |
| 25 (217) | Influence of dialect region on vowel perception and vowel production | Nicole Feeley* (Villanova University) Joseph Toscano (Villanova University) |
| 26 (218) | Does hearing impairment affect lexical competition? Interactive effects between word frequency, neighborhood density and hearing loss on auditory lexical decisions | Chad Rogers* (Union College) Brianne Dye (Washington University in St. Louis) Jonathan Peelle (Washington University in St. Louis) |
| 27 (219) | Evaluation of speech intelligibility in the presence of vocalized music in people with attention disorders | Olivia Kessler* (Lincoln University) David Heise (Lincoln University) |
| 12:30 | Lunch Break (60 minutes) | |
| Keynote Address | ||
| 1:30 | Working memory capacity and musical sophistication | Emily Elliott (Louisiana State University) |
| Music Perception | ||
| 2:00 | Correlation = causation: Music training, psychology, and neuroscience | E. Glenn Schellenberg (University of Toronto) |
| 2:15 | The perceptual structure of major and minor chords | Abigail Kleinsmith* (University at Albany, State University of New York) Vincenzo Belli (University at Albany, State University of New York) Jeff Bostwick (University at Albany, State University of New York) W. Trammell Neill (University at Albany, State University of New York) |
| 2:30 | Performer differences and conveyed emotion: how interpretation shapes listeners perception of emotion? | Aimee Battcock* (McMaster University) Mike Schutz (McMaster University) |
| 2:45 | A cross-cultural approach to narrative experiences of music | Devin McAuley* (Michigan State University)* Gabrielle Kindig (Michigan State University) Rhimmon Simchy-Gross (University of Arkansas) Carolyn Kroger (Michigan State University) Natalie Phillips (Michigan State University) Patrick Wong (Chinese University of Hong Kong) Elizabeth Margulis (University of Arkansas) |
| 3:00 | Break (15 minutes) | |
| Auditory Perception Across the Lifespan | ||
| 3:15 | Mismatch negativity to omissions in infants and adults | David Prete* (McMaster University) Laurel Trainor (McMaster University) |
| 3:30 | The effect of background type, spatial location, memory span and expressive language ability on speech in noise thresholds in young children | Douglas MacCutcheon (Gävle University College) |
| 3:45 | The role of tone duration in temporal processing for young and aging adults | Leah Fostick* (Ariel University) Harvey Babkoff (Bar-Ilan University) |
| 4:00 | Effects of age on spatial release from informational masking | Benjamin Zobel* (University of Massachusetts Amherst) Lisa Sanders (University of Massachusetts Amherst) Anita Wagner (University Medical Center Groningen) Deniz Başkent (University Medical Center Groningen) |
| 4:15-5:00 | Business Meeting (APCAM, APCARF, and AP&C) | |
Listeners can identify sounds in the environment quickly and easily. However, this impressive ability belies an interesting conundrum: sounds necessarily require time to develop. How do listeners leverage this unfolding acoustic information to identify the individual sounds they encounter? To probe the critical acoustic cues listeners use to identify sounds we curated a diverse set of natural sounds relevant to humans: speech from different speakers, different musical instruments and different everyday objects and materials. This duration constraint allowed us to leverage the temporal development of the acoustic features in the tokens to understand how listeners identify sounds following onset. We found that speech sounds were identified best at the most limited durations (25 to 50 milliseconds), while environmental sounds were identified best at longer durations (100 to 200 milliseconds). Mixed-effect models of identification and confusion rates among items revealed that participants based their responses on different spectrotemporal rates of change, aperiodicity and the spectral envelope cues.
Back to scheduleThe cacophony of alarms in hospitals contribute to a larger problem of alarm fatigue plaguing both patients and clinicians. Traditional alarms typically employ tones with flat amplitude envelopes. Flat tones are characterized by a sudden onset reaching maximum amplitude followed by a period of sustain, and a sudden offset. In contrast, natural sounds with percussive amplitude envelopes exhibit dynamically changing amplitudes characterized by a sudden onset reaching maximum amplitude followed by an immediate, exponential decay. Here we apply our team's theoretical work on amplitude envelope to issues of annoyance with alarms conforming to the International Electrotechnical Commission (IEC) 60601-1-8 standard. These alarms employ flat, melodic tone sequences informing clinicians about machine and patient-related problems in the intensive care unit (ICU). In experiment 1, we synthesized two versions of the current IEC alarms: flat alarms (composed with flat envelopes) and percussive alarms (composed with percussive envelopes) using pure tones. During the exposure task, participants were randomly exposed to either flat alarms or percussive alarms. Afterwards, participants completed a two-alternative forced choice annoyance task identifying which alarm version they perceived to be more annoying from a pair of alarms. During the annoyance task, all participants were exposed to both percussive and flat alarms but were naïve to the purpose of this task. We found that regardless of exposure condition, flat alarms are perceived to be more annoying. These results suggest sounds resembling naturally occurring sounds may be better at reducing annoyance. In experiment 2, we repeated the same experiment using complex tones to see if similar results could be observed using alarms with backwards compatible spectral structure. We found a similar pattern of results as experiment 1 suggesting envelope manipulation may reduce perceived annoyance, even in sounds with greater acoustical complexity. These results offer a simple, cost-efficient solution to reduce annoyance in the ICU while maintaining the current alarm-referent associations.
Back to scheduleAttention research has demonstrated that the level of perceptual load imposed by a task affects processing of additional information. Our recent work (Murphy & Greene, 2017) has demonstrated the cross-modal effects of perceptual load, with drivers experiencing high levels of inattentional blindness when attending to an auditory task (listening for information on the radio). The current study examined this effect in individuals who have experience in attending to high-load auditory information while driving; those who drive an ambulance as part of their job. While driving an ambulance, emergency medical professionals must also attend to auditory information conveyed over the radio, including updates on the patient's status, driving directions, etc. 60 drivers (29 ambulance drivers, 31 non-ambulance driving medics) attended to traffic updates on the radio while driving a short route in a driving simulator. As expected, awareness for an unusual object (a large roadside polar bear) was reduced under high, relative to low perceptual load for the controls (25% vs. 43%), however this was not the case for the emergency medical professionals (44% vs. 46%). This study suggests potential differences in the processing of auditory information in those who regularly drive an ambulance as part of their job.
Back to scheduleWhen producers plan long complex action sequences, multiple events are activated in working memory. Although expert performers can rapidly and precisely produce these sequences, occasional serial ordering errors occur. These errors reflect the simultaneous accessibility of sequence events during planning. Two measures characterize the relationship between the position associated with an ordering error (the intruder) and its intended sequence position. The direction of an error reflects whether an individual produces a previous event (perseveration) or anticipates a future event. The distance of an error reflects the number of sequence events separating the intruder's current and intended positions. Although serial ordering errors occur in the production of both speech and music, previous models of planning have focused on only one domain. We introduce a hybrid model of planning that integrates Direction constraints from an existing speech production model (Dell, Burger, & Svec, 1997) with a model of music production that addresses Distance constraints (Palmer & Pfordresher, 2003). We tested the hybrid model's predictions through fits to elicited errors from speech production and piano performance. Stimulus sequences used to elicit errors were matched on sequential complexity and metrical structure. Patterns of speech and music errors and best-fitting model parameters suggest that metrical structure guides planning in both domains, whereas anticipatory activations were far greater in speech than in music. These results suggest that the anticipatory tendency observed in speech production may arise not as a byproduct of sequential structure. Instead this tendency may reflect domain-specific weighting of the past and future based on long-term exposure to repetition rates of items, which is greater in music than in speech.
Back to scheduleNeural representation can be induced without external stimulation, such as in the process of mental imagery. Unique in the auditory domain is the tight connection between motor and sensory systems. Our previous study found that imagined speaking and imagined hearing modulated neural responses of auditory perception in different directions, suggesting auditory representation can be induced via motor-to-sensory transformation or memory retrieval (Tian & Poeppel, 2013). We hypothesized that the different modulation effects were caused by the precision of inducted auditory representation via distinct mechanisms. That is, because of the established one-to-one mapping between motor and sensory domains during speech production, motor-to-sensory transformation can evoke more precise auditory representation than that based on memory retrieval. In a computational model, we built in the factor of precision and its top-down function as the modulation of connection strength between acoustic and phonological layers in a neural network. The simulation results were consistent with MEG results of imagery repetition effects. Moreover, this model predicted that the precision differences in different types of auditory imagery would affect auditory perception differently. We tested this prediction in a behavioral imagery-adaptation experiment. Participants judged the /ba/-/da/ continuum stimuli after they either performed imagined speaking or imagined hearing. The psychometric curve showed positive shifts toward the preceding imagined syllables, but the shift was more prominent after imagined speaking than that after imagined hearing, quantitatively in line with the prediction generated in the computational model. These consistent simulation and behavioral results support our hypothesis that distinct mechanisms of auditory imagery can internally generate auditory representation with different degrees of precision and differentially influence auditory perception.
Back to scheduleWords in Semitic languages (e.g., Hebrew, Arabic) are created by non-linear combinations of morphemes, each denoting part of the meaning of the word. As many morphemes are shared across words, they create an auditory context that is unique to Semitic languages. We asked whether this consistent auditory context contributes to speech-in-noise perception (similar to other context effects described in non-Semitic languages), and whether the context effect depends on the perceptual task. To dissociate the auditory context effects from the effects of familiarity with specific words or morphemes, stimuli were non-words built of pseudo-morphemes that do not occur in Hebrew. Stimuli had two interleaved morphemes — a root and a vocalic pattern (the morpheme that carries information about the vowel structure of a Semitic word). In each experiment, two conditions were tested: a high-context condition in which stimuli shared the same vowel structure and a low-context condition in a number of different vowel structures were used. Stimuli were embedded in multi-talker background noise and signal to noise ratios changed adaptively to estimate speech thresholds. In experiment 1, participants (N=40) had to simply repeat what they heard and recognition thresholds were assessed. Thresholds were significantly lower (better) in the high-context (M = -2.3 dB, SD = 1.5) than in the low-context (M = -0.9 dB, SD = 1.8) group. In experiment 2, two words (either the same or different by one phoneme) were presented on each trial and listeners (N = 30) had to determine whether they were the same or not. Performance was similar the two groups (M = 0.1 dB, SD = 2.0). Together these data suggests that the auditory context created by Semitic morphemes can influence speech perception, but the effect is task dependent. When observed, the context effect does not depend on familiarity with the specific morphemes.
Back to scheduleOne of the foundational issues in speech perception is the extent to which top-down information from lexical representations can influence early speech perception. Behavioral measures have been insufficient to solving this debate because they cannot distinguish perception from categorization effects. Cognitive neuroscience measures such as event-related potentials (ERP), however, serve as useful tools for understanding speech sound encoding as it unfolds over time, thus allowing us to separate perception from later-occurring processes. Specifically, the auditory N100 ERP component has been shown to be an index of acoustic cue encoding and attention. In two experiments, we measured cross-modal sequential semantic priming effects on N100 responses. Participants saw visual primes that formed a clear association with the target ("MARCHING band"), led to no specific association ("BUTTER bomb"), or consisted of a nonword mask. Auditory targets were stop consonants varying in voice onset time (VOT), an acoustic cue signaling the difference between voiced and voiceless sounds. Stimuli included short/voiced (/b,d,g/), ambiguous, and long/voiceless (/p,t,k/) VOT values. Behaviorally, participants were faster to respond to the starting sound of the target in the Association prime condition than the Neutral prime and Mask conditions. In subjects' brain responses, we found the expected bottom-up effect of the stimulus VOT (larger N100s for shorter VOTs; Toscano et al., 2010). Additionally, in Experiment 1, we found that Association primes produced smaller N100s when targets were perfectly predictive, suggesting that listeners to attended less to those targets. In Experiment 2, ambiguous and unexpected VOTs were added to investigate whether semantic context changed how listeners encode sounds, and we found that ambiguous VOTs were encoded similarly to the voicing endpoint elicited by the prime in the Association condition. These results provide the first ERP evidence that top-down lexical information directly influences early perceptual responses through lexical-prelexical interactions.
Back to scheduleFor both normal-hearing and hearing-impaired individuals, there are large individual differences in the ability to understand speech in difficult listening conditions (e.g., attending to a single talker in a crowded restaurant setting). Speech understanding in the presence of competing sounds also generally declines with increased age. Although hearing loss contributes to declines in understanding speech in difficult listening situations, other factors, such as cognitive ability, have also been shown to play an important role. Some recent work suggests that music training may enhance speech-in-noise (SIN) ability, but results on this topic have been far from unequivocal. The present study investigated the role of speech rhythm in understanding speech in noise using the Coordinate Response Measure (CRM) paradigm. Participants listened to spoken sentences of the form "Ready [call sign] go to [color] [number] now" and reported the color and number of a target sentence (cued by the call sign "Baron") spoken by a target talker. The target sentence was presented amidst two-talker background sentences of the same form. Participants were randomly assigned to one of two conditions which held the rhythm of either the target or background sentences constant while varying the rhythm of the other. Results revealed that varying the rhythm of the background sentences, while keeping the rhythm of the target constant, improved listeners' ability to correctly report the color and number of the target talker; conversely, varying the rhythm of the target talker, while keeping the background rhythm constant, reduced listeners ability to correctly report the color and number of the target talker. The latter result was not simply due to reduced intelligibility of the target sentence, as varying the rhythm of the target sentence presented in isolation had no impact on listeners' performance. Results are interpreted in the context of Dynamic Attending Theory (DAT).
Back to scheduleMany adults report hearing difficulty, especially for understanding speech in noise. For some of these listeners, hearing difficulty may be caused by auditory neuropathy (AN), a disruption or loss of auditory nerve fibers (ANFs). AN may or may not be accompanied by elevated audiometric thresholds, suggesting instead that listeners with AN have difficulty coding supra-threshold sounds. Current models suggest that AN may be caused by damage to ANFs that code intensity differences at these higher sound levels, which can result in poorer temporal coding. In turn, this can disrupt speech recognition, as temporal coding may be critical for computing certain acoustic cues in speech (e.g., voice onset time). We predicted, therefore, that listeners with difficulty understanding speech in noise would show poorer intensity discrimination at higher sound levels, corresponding to those used in conversational speech. Listeners heard pairs of tones that differed by 1-5 dB and varied in frequency (500-4000 Hz) and overall intensity (20-70 dB SPL), and they judged which tone was louder. Self-report measures of hearing difficulty, including speech-in-noise difficulty, were obtained, along with pure tone thresholds. We found that listeners who experience greater hearing difficulty show poorer intensity discrimination, but only at sound levels typical of those used in speech (60-70 dB SPL). Moreover, this effect was unidirectional: listeners with greater hearing difficulty showed poorer performance when the first tone in the pair was louder and better performance when the second tone was louder. Thus, the effect is driven by a difference in the point of subjective equality between the two tones, rather than a difference in the threshold. In addition, listeners' pure tone thresholds did not correlate with speech-in-noise difficulty. The results suggest that differences in intensity discrimination may provide a robust test for AN. Implications for models of AN and diagnostic tests will be discussed.
Back to scheduleStuttering is characterized by deficits in motor planning and execution, but not cognition — impacting approximately 1% of adults (Bloodstein & Bernstein-Ratner, 2008). People who do not stutter (PWNS) may misinterpret stuttered speech as an indication of the speaker's cognitive state, because this is how normal disfluent speech is sometimes interpreted (Heller, Arnold, Klein, & Tanenhaus, 2015). Self-disclosure has been shown to reduce negative social perceptions associated with stuttered speech (Byrd, McGill, Gkalitsiou, & Cappellini, 2017), but it is currently unknown if self-disclosure impacts perception and cognition or if the behavioral change is associated with social desirability effects. The purpose of the current experiment was to evaluate changes in social judgements and cognitive processing of speech from a PWNS and simulated PWS through the digital prolongation of initial /ʃ/ in five words (sheet, shut, shoot, shirt, shot; Kawai, Healy, & Carrell, 2007) before and after the PWS speaker self-disclosed that he was a PWS. A computer mouse-tracking paradigm was used to evaluate ratings of speaker intelligence and measures associated with cognitive pull when making categorical ratings (e.g., reaction time - rt, x-flips, maximum deviation - max dev, and area under the curve - auc; Dale, McKinstry, & Spivey, 2007). Results indicated that PWS speech sounds were ~12 times more likely to be rated as unintelligent, relative to PWNS (p < .001), and after self-disclosure the PWS speech sounds were rated as more intelligent relative to baseline (p < .001). Analysis of the mouse-tracking data indicated that listeners exhibited significantly more cognitive pull (i.e., hesitation and indecision), as reflected by longer rt (p < .001), larger max dev (p < .05), and auc (p < .01) when rating the PWS, regardless of self-disclosure. This suggests that changes in explicit bias might be more related to social desirability effects, and not changes in cognitive processing.
Back to scheduleA growing amount of research has established evidence for a relationship between musical sophistication and cognitive ability (e.g., Okada & Slevc, 2018). Furthermore, a recent meta-analysis indicated that musicians with greater levels of experience tend to outperform those with less musical experience on tasks where the stimuli to be memorized are tonal (Talamini, Altoè, Carretti, & Grassi, 2017). However, the degree to which this relationship remains using reliable and valid measures of working memory capacity like complex span tasks (e.g., Unsworth, Heitz, Shrock, & Engle, 2005) has not been established, and many of the earlier studies had small sample sizes that were then further divided into two groups: musicians and non-musicians. Using participants from both a Department of Psychology and a School of Music to ensure a wide range of experience with music, we conducted two, large-scale individual difference studies. We created a novel complex span task that used tonal stimuli corresponding to notes from a familiar scale (Experiment 1; Equal Tempered) and one using tones that purposefully did not adhere to notes from any familiar scale (Experiment 2; Li, Cowan, & Saults, 2013). Additionally, we administered other measures including two complex span tasks without tonal stimuli and the Goldsmiths Musical Sophistication Index (Müllensiefen, Gingras, Musil, & Stewart, 2014). Across the two studies, the particular tones chosen as the memoranda for the complex tone span task did not lead to differences in the overall level of recall or to differences in the relationships with the other variables. Exploring these relationships further, the three types of complex span measures were examined individually, along with the subscales of the musical sophistication index and the two objective measures, melodic memory and beat perception. Implications for the measurement approach that is taken in future research on music and cognition are considered. Our findings reinforce the importance of the use of multiple measures of an individual construct.
Back to scheduleAlthough psychology students know that it is wrong to infer causation from correlation, scholars sometimes do so with impunity. Here we tested the hypothesis that the problem is especially pronounced among neuroscientists. We collected a sample of 114 articles published since 2000, each of which examined associations between music training and nonmusical behavior or brain structure or function. Articles were classified as neuroscience or psychology based on the journal, method, or laboratory. Raters blind to the hypothesis determined from the titles and abstract whether a causal inference was made. Inferences of causation were common in both disciplines, but the problem was particularly acute among neuroscientists, with the odds of inferring causation more than twice as great compared to psychologists. The results highlight a single-minded focus on plasticity among neuroscientists, and an apparent disregard for findings from studies of far transfer and behavioral genetics.
Back to schedulePrevious studies have shown that even untrained listeners can distinguish between major and minor chords, and reliably label them as sounding "happy" or "sad" respectively. In a series of experiments, we tested major/minor discrimination (with feedback) or happy/sad judgment (without feedback) of triads in either root position (tonic as lowest note), first inversion (3rd lowest), or second inversion (5th lowest). Surprisingly, discrimination of major versus minor and consistency of happy versus sad were poor for first inversions, relative to either root-position or second-inversion triads. The inferiority of first inversions was attenuated for tetrads, in which the lowest note was doubled an octave higher. This suggests that a major or minor third above the tonic is crucial for the major/minor distinction, but this implies that listeners must first establish which note is actually the tonic. In a follow-up experiment, components of root-position triads were presented dichotically. Major/minor discrimination was significantly better if the fifth was on the same ear as the tonic, than if on the other ear. Surprisingly, there was no such main effect of placement of the third (logically, crucial for the major/minor distinction). Position of the third interacted significantly with position of the fifth, however, such that discrimination was significantly better when the third and fifth were in the same ear. The results suggest that in some circumstances, the interval between the chordal third and fifth (minor for a major triad, and major for a minor triad) is informative to the major/minor distinction.
Back to schedulePerformers have the ability to shape the listener's musical experience, communicating their desired expression through the manipulation of psychophysical cues. The expressive intentions executed by performers have a marked effect on musicals parameters in performance such as tempo, articulation, vibrato, etc. (Gabrielsson & Juslin, 1996). A listener's understanding of the conveyed emotion can vary based on the expressive strategies performers use to convey emotion, therefore differences in performers' interpretative decisions can affect how emotional expression is communicated.
In this set of exploratory experiments, we investigate the influence of performers' interpretative choices on listener perception of conveyed emotion. For each experiment, thirty non-musician participants rated the perceived valence and arousal of 48 excerpts of Bach's Well-Tempered Clavier (WTC), as performed by one of seven renowned piano players included in Willard A. Palmer's analysis on the WTC (Palmer, 1994).
Using multiple regression and commonality analysis building on our past approaches (Battcock & Schutz, 2018), we will assess the contribution of piece, performer and as well as selected musical cues (attack rate, modality and pitch height) to determine what variables predict for listener ratings of emotion. Three-cue predictor models for each performer show varying adjusted R2 values, representing how much our model predicts for rating variability. This indicates how differences in performers' use of expressive cues influence listeners' ratings of expressed emotion, and subsequently how well our model can account for variance. We will discuss further results as well as the implications of performer interpretive decisions on our understanding of emotional communication in pre-composed music.
Listeners sometimes hear abstract music without lyrics in terms of imagined stories, as if they were listening to battles or love stories unfold instead of merely to trumpet fanfares or a violin line. Although music scholars have devoted considerable attention to developing theories to explain this phenomenon in terms of structural features (e.g., musical contrast) and extra-musical associations that can emerge within a culture (topicality), these theories have received almost no empirical investigation. Toward this end, this project takes a theory-driven, cross-cultural approach to investigate the factors that shape narrative listening; of interest were potential contributions of musical contrast and topicality to listeners' narrative engagement with music. Stimuli were 128 one-minute excerpts of instrumental music, half Chinese and half Western in origin. The excerpts varied systematically in contrast and topicality based on the ratings of independent sets of expert music theorists. Narrative experiences for these musical excerpts were assessed for listeners in two locations in the Midwestern U.S. in comparison to listeners in a remote village in rural China. Results reveal (1) similar high levels of narrative engagement with music across cultures with a bias to hear narratives (and enjoy excerpts) to a greater degree when listening to music from one's own culture, (2) a similar general pattern of narrative engagement with music for both the Western and Chinese listeners, but (3) relative independence across cultures in the excerpts triggering narrative engagement (and enjoyment) for both Western and Chinese excerpts. Finally, in data collected to date, topicality is the biggest predictor of hearing a story in response to a musical excerpt, but this appears to be true only for Western participants listening to Western musical excerpts.
Back to scheduleThe mismatch negativity (MMN) is an event-related response seen in EEG recordings in response to occasional changes (deviants) in a repeating sequence of sounds (standards), such as a change in pitch or an omission of a sound. The MMN has been observed in infancy in response to deviations in many sound features, including as pitch and intensity. MMN in infancy has been interpreted as reflecting prediction error (i.e., the predictive coding hypothesis), but it is possible that it simply reflects supressed neural firing to the repeating standard stimuli (i.e., the neural adaptation hypothesis). Finding MMN in response to unexpected sound omission deviants would rule out the neural adaptation hypothesis, as there would be no release from adaptation if there is no deviant stimulus. To test this, we collected electroencephalography (EEG) data from adults and 6-month-old infants during an auditory oddball paradigm. We presented one sequence of piano tones consisting of a standard (C4, 236 Hz), a pitch deviant (F4, 351 Hz), and an omission deviant. Deviants occurred randomly within the sequence and comprised 20% of all trials (10% pitch deviant and 10% omissions). Preliminary analysis of the event related potentials (ERPs) revealed a significant MMN to pitch deviants in both populations, but only adults showed MMN to omission deviants. The lack of an MMN to omissions suggests infant may not use predictive coding to extract regularities from sounds, and MMN responses in infants may primarily reflect neural adaptation to the standard stimulus. Our study suggests that there may be a developmental trajectory for predictive coding and future studies should investigate when predictive coding mechanisms emerge.
Back to scheduleThe aim of this experiment was to explore how speech-in-noise (SiN) perception in children is modulated by environmental factors such as the type of background and spatial configuration of speech and background sounds, and personal factors such as the cognitive and linguistic ability of the listener. Thirty-nine 5-7 year old children were assessed on measures of backward digit span (BDS) and expressive language (EL) tasks and speech in noise (SiN) perception. SiN perception was reproduced in a realistic virtual school auditory environment and measured adaptively in two spatial configurations, with the background either co-located or spatially separated from the target speech. Two backgrounds were used: one mainly producing energetic masking (speech-shaped white noise) and the other (a single interfering talker) mainly producing informational masking. Results indicated that BDS was predictive of SiN thresholds. Results indicated that spatial release from masking across was only significant for the single interfering talker. When participants were split according to high and low BES and EL ability, the High BDS group and Low EL groups benefitted the most from spatial release from masking. The relationship between digit span tasks and SiN is discussed in addition to how differences in cognitive and language ability assist or hinder spatial auditory processing in children.
Back to scheduleAging adults have difficulties in processing temporal information, especially when the stimuli are presented rapidly. In a previous study, we showed that for young adults, tone duration and inter-stimulus-intervals (ISI) were inter-changeable in temporal order judgments. This suggested that for young participants, tone duration and ISI carry the same temporal information for the judgment of temporal order. Consequently, TOJ thresholds measured as stimulus onset asynchrony (SOA) were similar across different tone durations. However, aging adults have been reported in the literature to have difficulty in temporal processing mainly when tone duration is short. This might suggest that for aging adults, tone duration and ISI are not inter-changeable and do not carry the same temporal information for temporal order judgments. We hypothesized that since aging is associated with decline both in temporal processing as well as in hearing thresholds, short duration tones will require relatively longer ISIs than long duration tones to successfully judge order, i.e., SOA thresholds will be longer for short tone durations than for longer ones. In the current study, adults aged 60-75 years, performed dichotic temporal order judgments under the same conditions as the young adults in our previous study: 1) tone durations of 10, 20, 30, or 40msec; and 2) ISIs that varied between 5-240msec. Contrary to our hypothesis, aging adults did not require much longer separations (ISI) between short duration sounds, than between longer duration sounds and yielded similar SOA thresholds for all tone durations. These results suggest that although aging adults have higher hearing thresholds, short suprathreshold stimuli carry the same temporal information as longer duration tones.
Back to scheduleSpatial release from informational masking (SRIM) describes the reduction in perceptual/cognitive confusion between relevant speech (target) and irrelevant speech (masker) when target and masker are perceived as spatially separated compared to spatially co-located. Under complex listening conditions in which peripheral (head shadow) and low-level binaural (interaural time differences) cues are washed out by multiple noise sources and reverberation, SRIM is a crucial mechanism for successful speech processing. It follows that any age-related declines in SRIM would contribute to the speech-processing difficulties older adults often report within noisy environments. Some research indicates age-related declines in SRIM (e.g., Gallun et al., 2013) while other research does not (e.g., Li et al., 2004). Therefore, the present study was designed to add clarity to two fundamental questions: 1) Does SRIM decline with age and, if so, 2) does age predict this decline independent of hearing loss? To answer these questions, younger and older participants listened to low-pass-filtered noise-vocoded speech and were asked to detect whether a target talker was presented along with two-talker masking babble. Spatial separation was perceptually manipulated without changing peripheral and low-level cues (Freyman et al., 1999). Results showed that detection thresholds were nearly identical across age groups in the co-located condition but markedly higher for older adults compared to younger adults when target and masker were spatially separated. Multiple regression analysis showed that age predicted a decline in SRIM controlling for hearing loss (based on pure-tone audiometry), while there was no indication that hearing loss predicted a decline in SRIM controlling for age. These results provide strong evidence that SRIM declines with age, and that the source of this decline begins at higher perceptual/cognitive levels of auditory processing. Such declines are likely to contribute to the greater speech-processing difficulties older adults often experience in complex, noisy environments.
Back to scheduleAcquired expertise has been shown to alter perception. Previous research from our lab has revealed a correlation between differences in auditory object perception and extent of formal music training. Additionally, we have shown that musicians rely upon specific sound features when categorizing objects, whereas non-musicians seemingly use no such strategy. We hypothesized that genre-specific training may bias attention towards unique sound features that influence the formation of auditory perceptual objects due to differences in sound features stressed during performance. Here, we tested whether musicians with differing (genre) training backgrounds rely upon similar sound features during judgments of musicality. Participants completed a prescreening survey designed to document formal music training and subjective measures of interaction with various musical genres. Survey results revealed a double-dissociation regarding comfort with deviations from musical notation: Classical musicians are more comfortable with deviations while listening to music, whereas Jazz musicians are more comfortable with deviations while performing. Participants were later tested behaviorally while listening to randomly generated pure tone "melodies", by rating the "musicality" of each. Classical and non-classical musicians showed a striking similarity in ratings. Correlations between ratings and six objective metrics of sound features (contour, key, etc.) showed no significant differences between subject groups. Furthermore, a remarkable number of the lowest (50%) and highest (82%) rated melodies were identical for classical and non-classical musicians. These results run counter to our predictions and suggest that auditory object perception may be surprisingly consistent among formally trained musicians of different genres. Thus, formal music study may cause prioritization of consistent low-level sound features, regardless of genre-specific training.
Back to poster listingThere have been many demonstrations of timbre's influence on pitch, but relatively few direct evaluations of pitch's influence on timbre. It has been argued that vowel identification is reduced as fundamental frequency increases (Ryalls & Lieberman, 1982), whereas instrument timbres have been claimed to be stable over a limited range of fundamental frequencies (Marozeau, de Cheveigné, McAdams, & Winsberg, 2003). Our laboratory's investigations using vowels (e.g., Assgari & Hall, 2013 APCAM) reveal a more complex relationship with pitch that depends upon the correspondence between energy from the source vibration and resonant frequencies determined by the size and shape of the filtering body. The current investigation further evaluated this possibility by applying shared methods to simplified, synthetic instrument timbres and vowels. Static spectral envelopes were generated from average measurements of harmonic amplitudes for productions by clarinet, trumpet and violin at a fundamental frequency of 220 Hz, as well as of /a/ and /i/ at 110 Hz. Stimuli were matched for duration and average amplitude across a three-octave range above the original production for each step within the A-minor scale. Listeners could repeatedly trigger each stimulus for each sound source, and assigned ratings of relative goodness as the intended instrument or vowel using a 7-point scale. Ratings decreased at higher fundamental frequencies, replicating findings implying that timbre suffers as adjacent harmonics spread apart. However, this effect was nonlinear and unique to each source. Ratings correlated best with average differences across 1/3-octave bands relative to signals at the lowest fundamental. Thus, changes in ratings primarily reflected changes in realized spectral envelopes. Furthermore, strong correlations were obtained even when bands were restricted to formant frequencies within the original signal, suggesting a reliance on intense frequencies in making timbre judgments. Broad implications for understanding the basis of interactions between pitch and timbre will be discussed.
Back to poster listingThe purpose of the current study was to investigate the effects of rise time on timbre perception using identification and multidimensional scaling techniques. Twenty young adults participated. Nine musical tones were synthesized having a fundamental frequency of 440 Hz (note A4) with seven harmonics, the same intensity, and duration of 300 ms. A series of 9-musical tones was generated altering the rise time in acoustically equal steps of 20 ms from 20 ms (short rise time) to 180 ms (long rise time). The results obtained from a two alternative forced choice identification measurement indicated that tones with rise times between 20 ms to 80 ms were perceived as plucked, whereas tones between 120 ms to 180 ms were perceived as bowed. The stimuli with mid-rise time between 80 ms to 120 ms had the longest response times. The data obtained by dissimilarity judgment were analyzed using an INDSCAL multidimensional scaling model and a perceptional distance map among nine stimuli was generated by the Euclidean distance model. As rise time increased, the values of dimension 1 were changed from negative to positive. The Pearson's correlation was conducted to see the relationships between identification and dissimilarity measures. There was a strong negative correlation between the dimension 1 and the identification percentage (r = -0.996, p < .000), whereas a strong positive correlation was found between the dimension 2 and the identification response time (r = 0.775, p = .014). Therefore, the significant effects of rise time that were obtained by the two different behavioral measures suggest that the temporal aspect of timbre is differently perceived by not only acoustical differences, but also experience variability of sounds.
Back to poster listingWe introduced wrong notes into familiar melodies, altering the pitches of arbitrarily selected notes by raising or lowering them by 1 or 2 ST, and leaving them in-key or moving them out-of-key. The alterations were completely counterbalanced and all occurred equally often. When we looked at the effects of the direction of the alteration (up or down) we found very small effects on detection of altered notes, but a significant interaction of direction by interval size. Whereas 2 ST alterations, up or down, were detected more accurately and quickly than 1 ST, for 1 ST alterations participants were slower in detecting down than up. We suggest this may reflect the prevalence of 1 ST deviations from main melody notes in such melodies as the chorus of The Stars and Stripes Forever and Tales from the Vienna Woods. This ornamentation with a semitone lower is much more prevalent than ornamentation with a semitone higher.
Back to poster listingUncovering the origin of music is a daunting and likely impossible task. Some theories assert that musical instruments - and some compositions - may have been constructed to replicate pleasant natural sounds, such as bird songs and insect chirps. One way to provide evidence for this claim is to examine the statistical structure of both bird and human songs. The current research used cross recurrence plots and fit approximations for several types of distributions to assess similarity. Human songs, unsurprisingly, display a high degree of recurrence of musical notes. Bird songs display less recurrence than human songs, though they do recur somewhat and the degree to which varies greatly depending on species. The distribution of jump distance between notes (e.g., two semitones or three whole steps) for both types of song are very similar. In fact, both are best modeled by exponential distributions centered on note movement of 0; the most likely note to follow any given note is itself. Birds with brain lesions that impair the song learning process typically exhibit much less enjoyable songs. When comparing these songs to normal birds, two things are clear. First, the recurrence rate is much higher, though not in a melodic pattern as seen in human songs. Rather, birds with vocal learning lesions persist in one note space for a long duration. Logically, this would seem to entail a well-defined peak when analyzing lesioned bird songs by note movement; namely, a high rate of 0 movement. However, this is not true. While 0 is, indeed, well represented, lesioned birds exhibit much wider variance in their mode activity and very few occurrences outside that range. Pareto distributions seem to fit lesioned bird songs best, though the fit statistics are very low for all distributions. Finally, participants rated sine wave representations of both bird and human songs as equally enjoyable but rated lesioned bird songs as significantly less preferred. These conclusions demonstrate that bird songs and human songs do share some statistical characteristics and, furthermore, that the characteristics they share are aesthetically important.
Back to poster listingCorrelations have been reported between rhythm perception and improvements in motor and cognitive functions. Examples include gait of individuals with Parkinson's disease and language tasks like grammar processing. Previous research also suggests that gait impairment is due to a deficiency in internal timing mechanisms. Due to the phenomenon of sensory-motor entrainment in rhythm response and pulse generation in humans, rhythmic auditory priming may enable the timing of motor activation to be synchronized with a pulse in a musical sound pattern; i.e., there appears to be a transfer effect between rhythmic stimulation and cognitive and motor functions of a sequential nature. We investigate the effects of rhythmic auditory stimuli on the activation of dopamine in cortico-striatal structures through a Leabra-type basal-ganglion (BG) model in the neural simulator Emergent, along with a cochlear model used to condition the inputs to the BG network. The cochlear model utilizes auditory processing methods included in the Emergent software package to create a realistic sensory input into the BG neural network. This exploration aims to shed light upon the roles rhythm plays on neural activation patterns related to dopamine reinforcement in motor-pulse generation.
Back to poster listingThe "bimanual advantage" is a phenomenon whereby timing variability in synchronization-continuation tapping with an auditory pacing stimulus is reduced when tapping with two hands compared to tapping with a single hand (Helmuth & Ivry, 1996). The mechanism underlying the bimanual advantage, however, is still poorly understood. Two experiments extend previous work on the bimanual advantage by (1) using high-resolution continuous motion-tracking, by (2) considering a methodological issue raised in previous work, and by (3) evaluating two competing explanations for the bimanual advantage: the multiple 'clock' hypothesis proposed by Helmuth and Ivry (1996) and an entrainment hypothesis (Schöner, 2002). High-resolution continuous motion-tracking data is used to analyze synchronization-continuation tapping. This novel tapping data allows us to precisely extract tapping time series' and examine movement dynamics. Experiment 1 replicates Helmuth and Ivry (1996) at three tapping tempi and considers the possibility that a portion of the bimanual advantage is an artifact of Weber's Law associated with a tendency to speed up tapping to a greater degree in bimanual compared to unimanual conditions. Experiment 2 revisits Helmuth and Ivry's multiple-clock hypothesis by comparing within-hand tapping variability when an individual taps with another individual — an interpersonal ('bimanual') tapping condition — compared to when they tap alone — a solo ('unimanual') tapping condition. For Experiment 2, the multiple-clock hypothesis predicts no interpersonal bimanual advantage whereas the entrainment hypothesis predicts that interpersonal tapping should reduce within-hand tapping variability compared to solo tapping. Results will be discussed with respect to these two hypotheses.
Back to poster listingMany complex actions (e.g., writing and speaking) are precomposed, by sequencing simpler motor actions. For such an action to be executed accurately, those simpler actions must be planned in the desired order, held in working memory, and then enacted one-by-one until the sequence is complete. Under most circumstances, the ability to learn and reproduce motor sequences is hindered when additional information is presented. However, in cases where the motor sequence is musical (e.g., a choreographed dance or a piano melody), one must learn two sequences concurrently, one of motor actions and one of the time intervals between actions. Despite this added complexity, humans learn and perform rhythm-based motor sequences regularly. It has been shown that people can learn motoric and rhythmic sequences separately and then combine them with little trouble (Ullén & Bengtsson, 2003). Also, functional MRI data suggest that there are distinct sets of neural regions responsible for processing the two different sequence types (Bengtsson et al., 2004). Although research on musical rhythm is extensive, few computational models exist to extend and inform our understanding of its neural bases. To that end, we introduce the TAMSIN (Timing And Motor System Integration Network) model, a systems-level neural network model designed to replicate rhythm-based motor sequence performance. TAMSIN utilizes separate Competitive Queuing (CQ) modules for motoric and temporal sequences, as well as modules designed to coordinate these sequence types into a cogent output performance consistent with a perceived beat and tempo. Here, we shall detail the mathematical structure of the TAMSIN model, present its results under various conditions, and then compare its results to behavioral and imaging results from the literature. Lastly, we discuss future modifications that could be made to TAMSIN to simulate aspects of rhythm learning, rhythm perception, and disordered productions such as those seen in Parkinson's disease.
Back to poster listingDuring entrainment, brainwaves rapidly synchronize with rhythmic stimuli. Dynamic attending theory hypothesizes that rhythmic patterns in speech and music enable entrainment of attention through neural resonance and generate temporal expectancies for future events. Most dynamic attending studies have been done with typically developed adults (TD), while little is known about rhythmic perception in children with Specific Language Disorder (SLI), a common, life-long communication disorder characterized by difficulties acquiring grammar and vocabulary. In children with typical development (TD), regular musical rhythm has a potentially positive influence on subsequent spoken grammar task performance. Children with Specific Language Impairment (SLI) have deficits in rhythm and meter perception along with the impairments in their lexical and grammatical abilities. This study provided additional evidence for the shared neural processing for language and music by investigating the difference in brain responses between the two populations with musical rhythm entrainment under the Dynamic Attending Theory framework. Using electroencephalogram (EEG), the study measured the brain responses evoked by two different repeating rhythms, strong-weak-rest and weak-strong-rest, while children listened passively. Participants were children with SLI (N = 14, Mean Age = 6;6) and those who are TD (N = 14, Mean Age = 6;9). The ERP analysis with the FieldTrip toolbox showed that both groups had a stronger entrainment effect under strong beats than weak beats, but were different in the length of latencies. In the 600 ms epoch, both TD and children with SLI have a stronger brain response to the strong beat in strong-weak-rest condition than to the one in weak-strong-rest condition, which supports the sensitivity to metrical structure. Cluster analysis was applied to test the latencies of significant cross-condition differences within each group. Both groups have two clusters indicating the distinguishable differences within conditions, but the group of SLI participants showed a much shorter latency for the negative cluster, indicating a relatively weak sensitivity to metrical structure (SLI: negative cluster 0.106 - 0.176s, p = 0.021, positive cluster 0.222 - 0.402s, p = 0.0001; TD: negative cluster 0.069 - 0.370s, p = 0.009, positive cluster 0.212 - 0.416s, p = 0.003). As a part of larger studies in the lab, these findings will facilitate future research on the correlations between language ability and neural entrainment to rhythm. For the next step, time-frequency analysis will be applied to take a deeper look into the frequency activity. The analysis that will look at possible correlation between brain responses and expressive language ability is underway.
Back to poster listingThe ability to quickly identify an image or sound in one's environment is influenced by a combination of both semantic and physical features. Some features are stable, such as whether the person is already familiar with that specific stimuli. Others are dynamic, such as how recently a related piece of information was encountered. The present research focuses on a machine learning analysis that builds a model to predict whether an identification response will be correct or incorrect using features such as self-reported familiarity and pleasantness, stimulus modality, and response time. Data were collected from a study of 21 participants that provided open-ended identification responses when presented with sounds and images. Each image had a matched sound and all stimuli were presented in a random order and at varying intervals. This analysis shows that the best fit model is a random forest decision tree algorithm, which achieves over 76% accuracy when holding a randomly selected 30% of the data as a test set for validation. A feature importance analysis determined that the driving feature was the modality of the target stimuli, with visual stimuli being highly correlated with correct responses. Self-reported familiarity with the stimuli, response time, and previous exposure to related information in the other modality also contributed strongly to the model; however, previous exposure to that exact stimuli was not highly influential to accuracy prediction. These results may help elucidate the cognitive and neural processes by which people are able to recall identifying information about common sounds and images.
Back to poster listingSounds with rising intensity are perceived as looming while falling-intensity sounds are perceived as receding. Looming objects may pose a threat to survival and audition functions as an early warning system to anticipate arrival time and allow time for behavioural avoidance responses. While it is known that individuals make over-anticipation errors for the arrival time of looming objects, to date no study has investigated whether looming and receding sounds differentially capture attention. In the current study, participants ignored looming or receding telephone ring-tones while undertaking a focal visually-presented short-term serial recall task. In four experiments we demonstrate that looming sounds produce more attentional capture than receding sounds, as indexed by the disruption they produce to serial recall. The differential disruption produced by a looming relative to a receding sound occurred regardless of its temporal point within the serial recall trial (Experiment 1 & 2) and could not be explained by the unexpectability of its offset compared to that of a receding sound (Experiment 3). However, boundary conditions for this looming effect were established since the effect was eliminated by the presence of a white noise masker (Experiments 1 & 2) and by increasing task difficulty (Experiment 4). The findings that the acoustical properties of looming sounds are automatically extracted and have the power to attract attention are consistent with the idea that looming objects constitute a class of stimuli with high biological significance that are prioritized by the attention system.
Back to poster listingResearch on auditory motion has demonstrated that we are more sensitive to sounds that are approaching rather than receding (Neuhoff, 2001), which may be driven by an evolutionary advantage to recognize approaching objects. The vast majority of the prior work in this area has focused on the movement of sound across one dimension. However, auditory information often occurs in more than one dimension in everyday life. Johnston et al. (2017) tested participants' perception of motion across two dimensions: distance and elevation. Using recordings of a person walking up and down a staircase, Johnston et al. found that individuals are highly accurate at judging whether a person is walking toward or away, but relatively poor at judging whether a person is moving up or down a set of stairs. The current study employed a similar method, but provided feedback after each sound. Participants were informed whether the sound was a person walking toward/away and up/down. The preliminary results showed that, when given feedback, participants were able to improve their performance over time. These results indicate that we are able to perceive motion in terms of elevation, but are relatively poor at doing so. We will discuss the time in which feedback is most beneficial and the implications for our understanding of auditory perception of elevation.
Back to poster listingPrevious studies have shown a bidirectional relationship between audition and vision. By that we mean audition influences vision and vice versa. For example, King (2009) found that while we can localize sounds based on auditory cues only, localization accuracy improves greatly if the sound source is visible. In the initial study by Johnston, Brown & Russell (2017), participants were exposed to audio recordings of a person walking up and down the stairs, either towards or away from the recording device. Findings revealed that participants were nearly perfect at perceiving whether the pedestrian was walking towards or away, but were only slightly better than chance when perceiving whether the pedestrian was moving up or down the stairs. The goal of the present study was to determine if the addition of visual stimuli would increase accuracy when perceiving motion direction in the vertical plane. Participants were randomly assigned to one of three conditions: (1) Audition Only, (2) Audition Paired with Static Visual Stimuli, (3) Audition Paired with Dynamic Visual Stimuli. The auditory stimuli were the sounds of footsteps on stairs. The static visual stimuli were pictures of the stairwells within which the pedestrian was audio recorded. The dynamic visual stimuli were animated motion videos involving a circle moving up or down the screen. The task of participants was to report whether the pedestrian was moving towards or away from them, and whether the pedestrian was moving up or down the stairs. The results will be discussed with respect to the extent to which visual stimulation enhances the auditory perception of motion in both the vertical and horizontal planes. The findings will also be discussed in terms of the degree to which vision enhances audition.
Back to poster listingNumerous studies have revealed that the accuracy of auditory judgments of sound source position are dependent on the method employed by the participant (e.g., Brungart, Rabinowitz, & Durlach, 2000; Loomis et al., 1998; Perret & Noble, 1995). Haber et al. (1993), for example, found a simple change in response method could decrease localization error twofold. However, the impact of response method on perceptual judgments has previously been limited to stationary sound sources. In real world settings, sound-producing objects often change position across multiple dimensions. The present study examined the extent to which alterations in response method significantly affected perceptions of a moving sound source. In a recent study by Johnston and Russell (2017), participants were exposed to the sounds of an individual walking toward or away from the recording device and either up or down a flight of stairs. Participants were given two 2-alternative forced choice tasks (state whether the person was approaching/withdrawing and going up/down the stairs). While participants were highly accurate at judging approach/withdrawal, performance at judging the direction of elevation change only slightly exceeded chance levels. Knowing their initial task was to judge the change in the horizontal plane (distance), participants attentional focus on that task may have impaired their ability to judge the change in elevation. If true, then altering the task of the participant may result in an increased ability to detect the change in elevation. Participants were randomly assigned to 1 of 3 conditions: (1) judge the change in horizontal and then vertical dimension, (2) judge the change in vertical and then horizontal dimension, or (3) judge only the change in the vertical dimension. Findings are discussed in terms of the importance of response method as well as attention as it relates to complex stimuli.
Back to poster listingWe use sounds to learn about events in the world, often without conscious reasoning. For example, we can judge the temperature of water simply from hearing it being poured (Velasco, Jones, King, & Spence, 2013). How do these nuanced cross-modal skills develop? Some aspects of cross-modal perception are present in infancy (Spelke, 1979), but many aspects are thought to depend on extensive experience (Gaver, 1993). We characterize the development of this cross-modal skill, asking if children can hear water temperature, and probing for developmental change over childhood. N=113 children were tested across a wide range of ages (3-12 years, M=5.83; 46 female). Acoustic stimuli were professionally recorded sounds of hot and cold water being poured into identical cups (from Velasco et al., 2013). Pre-test questions first established that children could identify images of hot vs. cold drinks/scenes, and identify other familiar sounds. Participants then heard sounds of hot and cold water being poured, and were asked to identify which sounded like hot vs. cold water. Stimulus order was randomized across participants. We found evidence of developmental change: Participants' age significantly predicted their accuracy (logistic regression, χ²(1)=12.91, p<0.001). Notably, preschool-aged children performed at chance (4 year-olds [n=37]: 40.5% correct; p=0.32; 5 year-olds [n=33]; 54.5%; p=0.73, binomial tests). In contrast, 85% of older children answered correctly (29/34 children age 6+). The ability to hear water temperature thus may not appear until mid-childhood, suggesting that this ability may require extensive auditory experience. This raises questions regarding the relevance of the experience required, and the extent to which children generalize (from experience with one liquid/temperature, to others). Overall, this work sheds light on the long trajectory of cross-modal auditory perceptual development in childhood.
Back to poster listingSuccessful navigation of information-rich, multi-modal environments requires that the most relevant sensory stimuli are selected and preferentially processed. However, many questions remain regarding how irrelevant auditory stimuli may change the focus of visual attention. The aim of this study was to examine the effect of a non-spatial, task-irrelevant sound on the processing of stimuli in the visual periphery. We utilized a version of the Eriksen flanker task in which participants are presented with three letters and asked to make a response based on the central letter. The flanker congruency effect (FCE) is a relative slowing in reaction time when the response assigned to the flanker letter does not match that assigned to the central letter (Eriksen & Eriksen, 1974). In our experiment, half of the trials were preceded by an irrelevant auditory beep. Sound is known to have a general alerting effect leading to decreased reaction times (Fischer, Plessow & Kiesel, 2010). Therefore, the auditory stimulus was predicted to cause general speeding of reaction time. Existing literature suggests that spatial attention may be modified by an observer's alertness (e.g. Kusnir et al., 2011). In this case we hypothesized that the FCE would also be modulated in the condition with sound, suggesting differential processing of peripheral flankers. Results confirm the alerting sound significantly speeded reaction time overall. The sound also modulated the congruency effect, with the reaction time benefit for congruent conditions being greater than that for the incongruent condition. These results suggest that nonspatial sounds may alter how peripheral visual stimuli are processed.
Back to poster listingChange deafness is a perceptual phenomenon that occurs when an observer fails to rapidly detect an above-threshold change in a sound source. The present research represented an initial investigation into one stimulus factor, the perceived similarity between array events, that potentially gives rise to change deafness to continuously moving target events. Participants (N=13) were presented with arrays of three simultaneous, synthetic /a/ and /i/ vowels. Each array event had a distinct pitch [low (A3), middle (D#4), high (B4)] that was inharmonic relative to the other events, as well as a unique starting location in perceived (virtual) space along the azimuth (-40°, 0°, +40°). Participants were instructed to identify the pitch of the tone that changed with respect to location in perceived space. The target, or changing event, had either a shared vowel with another distractor, thereby increasing perceptual similarity to another event, or had a unique vowel relative to the remaining two events. Mean percent correct identification of change was significantly lower when the target event was similar to distractors (less than 47 percent vs. greater than 60 percent under conditions with dissimilar events), indicating frequent incidence of change deafness that increases with increasing similarity between array events. Furthermore, there was a tendency for listeners to be less accurate when the target events began in the center position, presumably because those target events could move in either of two directions (twice as many as for the alternative starting positions). Additional analyses are examining whether task accuracy improved with musical training that increased the amount of active listening to isolate target sounds within performances by instrument ensembles. Implication of the results for models of change deafness, as well as their relation to models of change blindness in vision, will be discussed.
Back to poster listingThe directional Stroop task (e.g., Brooke, 1998) creates interference between a directional word and a directional cue, such as an arrow. This study was conducted to replicate directional Stroop interference using bimodal stimulus pairs and then to determine whether or not interference occurs when the word is replaced with a sound. In Experiment 1, an arrow, pointing up or down, was paired with an auditory word (UP or DOWN). Subjects were faster responding to the direction of the arrow when the pairs were congruent compared to incongruent indicating interference. In Experiment 2, the auditory word was replaced with the sound of a slide whistle either going up or going down. Although response times were longer for incongruent pairs, there was no significant interference between the arrow and a direction-related sound. Experiment 3 utilized the same design as Experiment 2. However, in Experiment 3 subjects responded to the direction of the sound instead of the arrow. Interference was found for incongruent trials. Together, the results replicate previous research with a bimodal task but also show a differential effect for auditory and visual distractors.
Back to poster listingA recent study showed that face recognition is disrupted by irrelevant music played at encoding. Joyful music with many abrupt auditory changes was found to be more disruptive than touching music without such changes. This finding parallels previous findings showing that the detrimental effect of irrelevant sound on serial short-term memory is primarily determined by the number of abrupt auditory changes in the distractor material (the changing state effect). In the present study, we tested whether a changing state effect on face recognition can be obtained with irrelevant speech as well. Participants encoded faces either in quiet or while ignoring steady state sequences (repeated words) or changing state sequences (sentences). The results suggest that effects of auditory distraction generalize to memory tasks involving non-verbal material.
Back to poster listingPast research has demonstrated that human voices contain far more information than the content and intonation of a statement. Attractiveness of the speaker is one such piece of information; ratings of vocal attractiveness are correlated with facial attractiveness (O'Connor et al., 2012). Another, possibly related piece of information is the overall quality of the voice. The current research defines acoustic properties used to identify both of these traits and those that set them apart. Thirty-four participants rated, in randomly determined blocks, both the preference and attractiveness for 50 different voices (25 male and female) and then rated the facial attractiveness of the corresponding speakers. The correlation between facial and vocal attractiveness was replicated (r = .38); there was not, however, a correlation between preference and facial attractiveness, highlighting the two as distinct sets of information that listeners are able to cognitively differentiate. Pitch was identified as an important indicator for attraction, while consonance was identified as a quality of equal importance for both attraction and preference. Using multidimensional scaling, consonance was found as a primary dimension (r = .58) on which both constructs are organized, which mirrors other work showing consonance as a primary organizational dimension (Patten & McBeath, 2017). While past research has identified categorical qualities that can determine preference of a voice (Zuckerman & Miyake, 1993), the current research offers concrete, measurable dimensions that can be used (and highlighted) in broadcasting, advertising, voice synthesis, and compression algorithms.
Back to poster listingWhat determines whether we integrate the auditory and visual events that we experience? One cue is whether the sounds and visual objects semantically belong together (e.g. a bouncing sound goes with a ball). But, we sometimes accept implausible sound events; for example, ventriloquists can make a puppet appear to be speaking if its mouth moves in synchrony with the speech. Is temporal congruence always sufficient for auditory-visual integration? Conversely, can semantic congruence influence whether an audiovisual event is perceived as temporally congruent? To address these questions, participants viewed movies of complex multimodal events. Both semantic and temporal congruence of the visual and auditory events were manipulated independently. Participants were asked to judge the synchrony of visual and auditory events in these short videos. Both accuracy and reaction time were measured. Videos contained either single or multiple events (e.g. a single knock on a door, or several knocks in a row). For benchmark purposes, some videos were briefly-flashed circles paired with beeps. Participants' sensitivity to temporal asynchrony interacted when the sounds and visual events either semantically matched or mismatched.
Back to poster listingIn Monty Python's famous 1969 song, when a (guy imagining himself as a) lumberjack talks about his wish to wear women's clothes, the choir and the audience are shocked, as it violates their expectations. Fifty years later, we tested whether, and to what extent, do gender-related implicit biases (regarding professions) still impact speech processing. In other words, does the spoken word doctor serve as a contextual cue for male? And how long it takes the listener to adjust, when the spoken sentence reveals that the doctor is in fact a woman. To test this in the lab, we first identified professions that were considered as most feminine (assistant, nurse) or masculine (lumberjack, doctor). Next, we adapted the visual world eyetracking paradigm. Listeners were asked to follow spoken instructions referring to one of four depicted professionals on a monitor. As the spoken sentence unfolds, the listener may learn that gender-based assumptions were incorrect. For example, "point at the doctor who is holding her phone". As the spoken sentence unfolds in time, listeners' eye-movements are tracked, revealing the timeline for identifying the target word (female doctor) and consideration of alternatives (male doctor), providing a highly sensitive and continuous measure of word processing. Our preliminary data supports the Monty Python song. When a gender-stereotypical profession was heard, fixations were more likely on the gender congruent picture (e.g., male doctor) than the in-congruent one (female doctor). As a consequence, spoken sentences depicting gender in-congruent professions take a toll on recognition. We suggest that implicit associations may serve as a syntactic-like context, which can speed-up speech processing if correct and slowdown processing if incorrect. Finally, we hope that this tool can serve in the future as a gauge for individual differences in implicit associations, measuring its impact on speech processing, rather than explicit self-reports.
Back to poster listingPrevious studies have reported musicians' have better speech-in-noise (SIN) recognition than nonmusicians. Others have failed to observe this "musician SIN advantage". Here, we aimed to clarify equivocal findings and determine the most relevant perceptual and cognitive factors that do and do not account for musicians' benefits in SIN processing. We measured performance in musicians and nonmusicians on a battery of SIN recognition, auditory backward masking (a marker of attention), fluid intelligence (IQ), and working memory tasks. We found that musicians outperformed nonmusicians in SIN recognition but also demonstrated better performance in IQ, working memory, and attention. SIN advantages were restricted to more complex speech tasks featuring sentence-level recognition with speech-on-speech masking (i. e., QuickSIN) whereas no group differences were observed in non-speech simultaneous (noise-on-tone) masking. This suggests musicians' advantage is limited to cases where the noise interference is linguistic in nature. Correlations showed SIN scores were associated with working memory, reinforcing the importance of general cognition to degraded speech perception. Lastly, listeners' years of music training predicted auditory attention scores, working memory skills, general fluid intelligence, as well as SIN perception (QuickSIN scores), implying that longer durations of musical training enhance perceptual and cognitive skills. Overall, our results suggest (i) enhanced SIN recognition in musicians is due to improved parsing of competing linguistic signals rather than signal-in-noise extraction, per se and (ii) cognitive factors (working memory, attention, IQ) at least partially drive musicians' SIN advantages.
Back to poster listingAs listening conditions worsen (e.g., background noise increases), additional cognitive effort is required to process spoken language. The existing literature is mixed on whether and how cognitive traits like working memory moderate the amount of effort that listeners must expend to successfully understand speech. Here, we validate a dual-task measure of listening effort (Experiment 1) and demonstrate that effort increases as listening conditions worsen, but individuals' working memory capacity is unrelated to the amount of effort expended (Experiment 2). We propose that previous research may have overestimated the relationship between listening effort and working memory by measuring listening effort using recall-based tasks, but the relationship between the two disappears when using a measure of listening effort that does not require recall. These results suggest caution in making the general assumption that working memory capacity is related to the amount of effort expended during a listening task.
Back to poster listingVowel sounds vary between regional dialects of American English, but it is unclear how listeners' vowel perception varies as a function of their dialect. In the present study, subjects completed a vowel identification task where they heard synthesized vowels varying along F1 and F2 continua and identified the sounds as /u/ ("boot"), /ʌ/ ("but"), /oʊ/ ("boat"), or /α/ ("bot"). Participants also completed a production task where they read the same words to allow for measurement of the acoustic characteristics of their vowels. Lastly, they completed a residency questionnaire to determine which of the six regional dialects of American English (based on those identified in the Telsur Project; Labov, 1997) they had lived in the longest. For the production data, we found a main effect of vowel category and gender for both F1 and F2, as expected. There were also differences based on dialect, such that talkers from the Midland region produced significantly higher F2 values and marginally higher F1 values for /o/. For perception, there was a main effect of F1 and F2 and an interaction between F1 and F2 on listeners' categorization of the vowels, but no effects of dialect. An analysis of participants' category boundaries suggested differences in production based on dialect (higher F1xF2 category boundaries for Midland speakers), but no differences in perceptual boundaries. Thus, while dialect affects F1 and F2 values for vowel production, vowel perception does not appear to be influenced by dialect. This suggests that listeners may not rely on their own prior experience of dialect when encountering an unknown talker, but instead may assume the dialect of the talker (i.e., that they were a Midland talker). The results help us better understand how speech sounds vary across different dialects and clarify what information listeners use to make inferences about novel talkers.
Back to poster listingThe Neighborhood Activation Model (NAM) holds that successful word recognition relies on acoustic-phonetic matching of speech to representations in the lexicon which compete on the basis of phonetic similarity. Words that phonetically overlap with many other words come from dense neighborhoods, whereas those that overlap with fewer words come from sparse neighborhoods. Previous work using the auditory lexical decision task (ALDT), where listeners indicate whether an aurally presented speech utterance is a word, has supported the NAM. For example, Goh, Suárez, Yap, & Tan (2009) showed using the ALDT that recognition of dense words is slowed relative to sparse words, and that words more frequently heard in the English language are recognized more quickly than low frequency words. Lexical competition becomes increasingly important in listeners with hearing loss, for whom the acoustic input signal has become degraded. In the current study, we investigated whether activation-competition dynamics between neighborhood density, word frequency, and ALDT performance observed by Goh et al. (2009) would extend to a sample of older adults with varying degrees of hearing loss. To that end, a sample of 30 older adults with hearing loss performed the ALDT. Words came from lists that were designed to be either lexically dense or sparse, along with an orthogonal manipulation of word frequency. We examined accuracy, mean reaction time, and ex-Gaussian parameters of participants' reaction time distributions. Results revealed older adults with hearing loss were faster for high than low frequency words, but did not show a significant effect of density. However, ex-Gaussian analyses revealed several 3-way interactions between hearing loss, neighborhood density, and word frequency. Implications of these results will be further discussed in terms of the impact of hearing loss on lexical competition dynamics, speed-accuracy tradeoffs, and individual differences in hearing and cognitive ability.
Back to poster listingAuditory processing disorder (APD) and ADD/ADHD (henceforth, simply ADHD) have numerous overlapping symptoms, causing them to be easily mistaken for each other and leading to misdiagnoses. In fact, there is an ongoing debate between the American Psychiatric Association and audiologists about the existence of APD as a separate disorder. We plan to explore the relationship between ADHD and speech intelligibility to shed light on this debate. Our first objective is to determine the percentage of ADHD subjects (both ADHD and non-ADHD) that meet the already determined threshold for APD. Our second objective is to determine whether ADHD subjects have a score lower than non-ADHD subjects. Our third objective is to test the impact of vocalized music on speech comprehension. We expect that the presence of vocalized music will have a negative impact on speech intelligibility, and we expect this effect to be more pronounced for the ADHD group. Our test population will be given an online hearing screening to eliminate those with actual hearing loss. We will then use ADHD and APD surveys to determine self-reported baseline symptoms. To test the impact of music (both instrumental and vocalized) on speech intelligibility, we will mix recorded sentences from the QuickSIN test from Auditec with excerpts from recorded popular music. We plan on testing subjects in separate background noises (babble noise, white noise, instrumental music, and vocalized music) in six different SNR levels (0 to 25 dB, in 5 dB increments). We know that those with ADHD suffer from an inability to concentrate; therefore, we suspect that the ADHD group will score less on a speech intelligibility test than those without ADHD and/or APD. We also suspect that the subjects will score less in vocalized music, with APD and ADHD groups demonstrating similar trends, since both disorders share the symptom of being easily distracted.
Back to poster listing